Basically these are the only things I know about Bash :). These aren’t all truly Bash commands, but instead these are common commands that everyone should know when using the Linux or Mac command line.
Notes
First, the command follows the $ and is listed in bold, the == is just a spacer, and everything else is a description of the command. The <> symbols designate where some other name should go there (like a file, folder, username, etc). The * symbol designates a wildcard, and can be used in conjunction with a partial search term. This means *.txt matches file.txt, file1.txt, etc.
Very Basics Commands
$ Ctrl + C == Kill whatever is running in the foreground
$ tab == complete current typing
$ <command> –help == lists options of a given command
$ Ctrl + A == Go to the beginning of the line you are currently typing on
$ Ctrl + E = Go to the end of the line you are currently typing on
$ Ctrl + U == Clears the line before the cursor position. If you are at the end of the line, clears the entire line.
Where Am I and How to I Move Elsewhere?
$ pwd == print working directory
$ cd == change directory
$ cd / == go to root
$ cd .. == go up one level
$ ls == list files and folders
$ ls -a == list all files and folders (including hidden)
Basic File/Folder Manipulation
$ mkdir <folder name> == create new folder
$ cp <old file name> <new file name> == copy and rename a file
$ mv <file> <folder> == move file to a folder
$ rm <file> == delete file
$ rm -r <folder> == delete folder
$ cat <file> == show content of file
$ head -n <number of lines> <file> == show top n lines of file
$ tail -n <number of lines> <file> == show last n lines of file
Nano
This is a basic file editor
$ nano <existing file> == opens up a file
$ nano <non-existing file> == creates and opens up a file
Within nano, the needed commands are listed at the bottom where the ^ symbol stands for Ctrl.
What is currently running? Can I stop it?
$ top == list all processes running on a computer
$ top -u <username> == lists processes being run by username
$ kill <pid> == kill a process identified by pid, which can be found by using top
$ killall -u <username> == kills all processes being run by username
How to run stuff in the background
$ <command> & == runs command in background
If you want to run jobs on a remote server, there will be some queueing system. Check out useful commands like qsub, qstat, etc. However, if you just want to run multiple processes on a single computer (even after logging off), Screen and Tmux are the tools you need. I personally use screen, and below are some useful commands.
Screen
$ screen -S <name> == new screen with name
$ Ctrl-a d == detach from screen
$ screen -r name == reattach to screen
$ screen -ls == list of screens
$ exit == kills currently attached screen
Example Running Code in the Background
Here is an example set of commands that will run a Python script in the background.
$ screen -S test
$ python test.py > out.txt 2>&1 &
$ Ctrl-a d
You now can safely exit and the computer will do all the tough work for you!
I did add one new command in there, the redirect (>). What this means is that Python runs test.py. If there is anything that should be printed to the terminal, it gets redirected and saved into the file out.txt. Otherwise when you reattach to the screen named test, you will just get the recent terminal output (usually there is some display length limit).


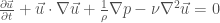
 is the velocity vector,
is the velocity vector, 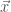 is position,
is position,  is density,
is density,  is pressure, and
is pressure, and  is the
is the  , length
, length 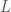 , and introducing the
, and introducing the 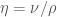 . This gives the following dimensionless variables:
. This gives the following dimensionless variables:

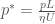



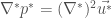
 and in a footnote identifies as the Sherwood number. However, Ben Regner pointed out, that Purcell’s
and in a footnote identifies as the Sherwood number. However, Ben Regner pointed out, that Purcell’s 
 is Brownian (standard diffusion),
is Brownian (standard diffusion), 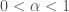 is subdiffusive,
is subdiffusive,  is superdiffusive, and ballistic is
is superdiffusive, and ballistic is 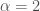 . So the technical definition of anomalous diffusion is
. So the technical definition of anomalous diffusion is 