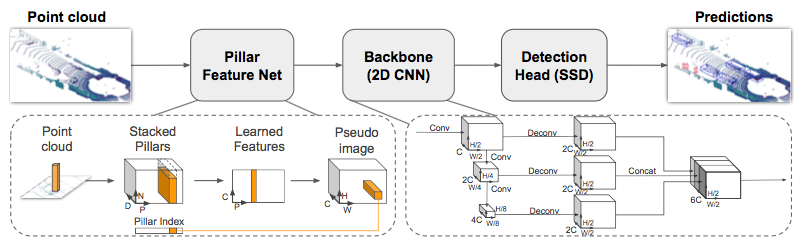
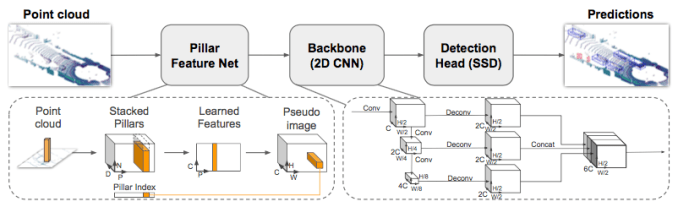

I’m excited to finally be able to share some of the stuff I have been working on since joining nuTonomy: an Aptiv company. We recently released our paper on PointPillars (with code), a cutting edge method for object detection using point clouds.
First, what problem are we trying to solve? Our company goal is to create the software stack to run a self driving taxi. Specifically, the machine learning team’s charter is to tackle the problems that are too tough to model explicitly. Therefore, our method of choice is deep learning, and we usually work closely with the raw sensor data. Our cars have a 360 degree coverage through multiple lidars, cameras, and radars (check out nuScenes for our actual data!), but of these lidar is the most important sensor. Lidar is a laser ranging sensor that provides sparse, yet accurate, points in the 3D world. These point clouds are the key inputs for 3D object detection since they allow precise localization in the real world.
The ideal deep learning model would incorporate all sensor modalities (lidar, cameras, and radar), but a first step is to separately model each sensor. Images are relatively easy since a multitude of methods exist in the literature, so our research has focused on how to do lidar and radar. I’m going to keep focusing on lidar since it is the main sensor, but everything that follows about PointPillars could equally well be used on radar after a few minor changes as I’ll explain later.
So, what was the state of the art for lidar only object detection when we started our research? There were two main schools of thought that are best represented by PIXOR and VoxelNet. The fundamental difference is how to represent the sparse lidar point cloud. One school of thought (PIXOR, MV3D, …) is to create a set of fixed, hand crafted features. The other school (PointNet, Frustum PointNet, VoxelNet, SECOND) believes in end to end learning and just lets the network learn directly from the point cloud. From a performance and engineering perspective, end to end learning is always better because (1) the network should always be able to match (and usually far exceed) fixed encodings and (2) we let the network do the hard work of finding the encoder, rather than having to devote engineer’s time to discover the right encoding. So we should all do end to end learning!
But there is always a catch. The issue with VoxelNet is that it is too slow to run in realtime. The central problem is that they chose to do end to end learning on voxels. This forces them to use 3D convolutions which are extremely slow. In contrast, PIXOR can just use 2D convolutions which are well optimized for GPU computing. If only there was a way to blend the performance of end to end learning with the speed of fixed encoders.
It turns out, we found a method to do so: PointPillars. The fundamental realization (courtesy of Oscar Beijbom) was that pillars are the best representation. A pillar is a vertical column that can extend infinitely up and down. By learning end to end on pillars, we achieved state of the art detection performance on the KITTI leaderboard at blazing fast speeds (60 to >100 Hz), for a 2-4 fold improvement in runtime.
A few more details on why we are so fast. First, by using pillars, we eliminate 3D convolutions since we immediately learn a 2D representation. Second, we sped up the network by eliminating parameters in the encoder and network. Third, while our initial model for training is in PyTorch, we convert that model to a NVIDIA TensorRT planfile which allows additional optimizations for GPUs.
So where do we go from here? The next step is to work on sensor fusion. First, we need a radar network, which at first glance looks like it might require more work. But it turns out, radar is also a sparse point cloud of range returns. While lidar points return the x, y, z position and reflectance of an object, radar returns the radial range, angular velocity, and a host of other features. So we can just plug in radar point clouds to PointPillar and go! Since the radar returns have worse spatial localization than lidar, it turns out the radar only network doesn’t give great performance. Finally, now that we have separate networks for lidar, images, and radar, it is time to fuse them together! We are actively working on this now and hopefully I can share some of our tricks soon.
