This is part of my “journal club for credit” series. You can see the other computational neuroscience papers in this post.
Unit: Deep Learning
- Perceptron
- Energy Based Neural Networks
- Training Networks
- Deep Learning
Papers
A Learning Algorithm for Boltzmann Machines. By Ackley, Hinton, and Sejnowski in 1985.
Learning representations by back-propagating errors. By Rumelhart, Hinton, and Williams in 1986.
Other Useful References
- Boltzmann Machine (BM) – Wikipedia and Scholarpedia
- MacKay Ch 43 (Boltzmann).
- Hinton guide to RBMs
- Backpropagation – Wikipedia
- Multilayer perceptron (MLP) – Wikipedia
- Michael Nielsen Chapter 2
How do you actually train neural networks?
Hopefully the past few posts have piqued your interest in neural networks. Maybe you even want to unleash a neural network on some data. How do you actually train the neural network?
I’m actually going to keep this brief for two reasons. First, detailed derivations can already be found elsewhere (for Boltzmann see Appendix of the original paper as well as MacKay, for backpropagation see Nielsen). Second, I firmly believe that algorithms are best learned by actually stepping through the updates, so any explanation I attempt will not be sufficient for you to truly learn the algorithm. I will provide some general context as well as some questions you should be able to answer, but please go do it yourself!
There are three general classes of machine learning based on the information received:
- Unsupervised – data only. Boltzmann machine.
- Supervised – data with labels. MLP with backpropagation.
- Reinforcement – data, actions, and scores associated with each action. Deserves its own detailed post, but check out papers by DeepMind for cool applications.
The Boltzmann machine learning rule is an example of maximum likelihood. In practice, the original learning rule is too computationally expensive, so a modified algorithm called contrastive divergence (or variants such as persistent contrastive divergence) is utilized instead. See the Hinton guide to RBMs for more details.
Backpropagation is a computationally-efficient writing of the chain rule from calculus, so besides the above paper which popularized it, there is actually a long history of this algorithm being discovered and rediscovered.
Fundamental Questions
- What is maximum likelihood?
- Why can one interpret the learning terms in the BM algorithm as “waking” and “sleeping”?
- Why are BM hidden layers so important?
- Why are restricted Boltzmann machines, RBMs, much easier to train?
- Why is backpropagation more computationally efficient than the finite difference method?
- Derive the 4 backpropagation equations!
Advanced Questions
- Follow Hinton’s RBM guide and implement your own Boltzmann machine
- Use Nielsen’s code to train your own MLP
 neuron. I will define a neuron’s state as
neuron. I will define a neuron’s state as  and neuron
and neuron  (out of
(out of  total) is firing if
total) is firing if  and not firing if
and not firing if  .
. of them) that one wants to store as
of them) that one wants to store as  where
where 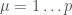 . The idea is to define the interactions between neurons as:
. The idea is to define the interactions between neurons as:

 ) by examining the activation function of the first neuron.
) by examining the activation function of the first neuron.


 . Second, we will assume that memories are not biased (equal numbers of neurons are on and off). Third, we will assume that we are storing random memories. Then using the central limit theorem, we get that on average,
. Second, we will assume that memories are not biased (equal numbers of neurons are on and off). Third, we will assume that we are storing random memories. Then using the central limit theorem, we get that on average,  . (Advanced question: what is the standard deviation of the noise term? What does that imply about stability of memories?)
. (Advanced question: what is the standard deviation of the noise term? What does that imply about stability of memories?)
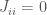 ). Using similar arguments as above, one can show that on average each memory has an energy of
). Using similar arguments as above, one can show that on average each memory has an energy of 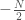 and that a flipping a single spin leads to higher energy. (Fundamental question: prove these statements!)
and that a flipping a single spin leads to higher energy. (Fundamental question: prove these statements!) , and create a dynamical system with these memories as global minima.
, and create a dynamical system with these memories as global minima.
 are visible neurons and
are visible neurons and 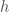 are hidden neurons (if present, not a requirement). There are three different types of interactions, those amongst visible neurons only (
are hidden neurons (if present, not a requirement). There are three different types of interactions, those amongst visible neurons only (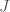 ), those amongst hidden neurons only (
), those amongst hidden neurons only ( ), and those between visible and hidden neurons (
), and those between visible and hidden neurons (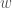 ).
).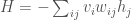
 and/or correlated with each other?
and/or correlated with each other?