This is part of my “journal club for credit” series. You can see the other computational neuroscience papers in this post.
Unit: Diffusion
Organized by Ben Regner
- Standard Diffusion
- Anomalous Diffusion
- Life at Low Reynold’s Number
Papers
Life at Low Reynold’s Number. By Purcell in 1977.
Other Useful References
Introduction
This is one of my favorite papers. The presentation style is extremely fun and readable without sacrificing any scientific integrity. I think it serves as a great introduction to fluid mechanics at low Reynold’s number. I don’t have too many comments since I think the paper explains it the best, but I will provide a few supplementary details for a more in depth exploration of the ideas from the paper.
And just to get you excited about fluid dynamics, I present an example of laminar flow:
Basics of Fluid Mechanics
The fundamental equation of fluid mechanics is Navier-Stokes. The relevant version for this paper is the incompressible flow equations with pressure but no other external fields:
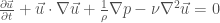
where 
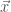




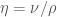


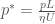

Substituting in these characteristic length scales and doing some algebra, one arrives at the simplified equations:

with only one dimensionless constant, the Reynold’s number, defined as:

As explained in the paper, Reynold’s number is one of the essential constants describing a flow. High Reynold’s number leads to turbulent (chaotic) flow, while low Reynold’s number leads to laminar (smooth) flow. For extemely small Reynold’s number, Navier-Stokes simplifies to:
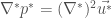
which is also just called Stoke’s equation.
At the end of the paper, Purcell describes another dimensionless number which he calls 
Basics of Ecoli Chemotaxis
Chemotaxis and cellular sensing really deserves its own series of papers. But in the meantime, I recommend the following resources
- Chemotaxis on Wikipedia
- Howard Berg’s videos on individual Ecoli
- Howard Berg’s videos on swarms of Ecoli
- Berg and Purcell, Physics of chemoreception, 1977.
Video Proof of Purcell’s Scallop Theorem
Reversible kicking does fine in water (high Reynold’s number)…
… but the same motion has issues in corn syrup (low Reynold’s number).
Here is a solution similar to what Ecoli and other bacteria employ.
Fundamental Questions
- Purcell does an amazing job, so I have nothing to add.
Advanced Questions
- What are some other strategies that are employed in biology to get around the issue of mobility at low Reynold’s number? Hint: I already linked to a video of one strategy. There are at least two other strategies, but to find these you will need to think about the assumptions leading to the basic Navier-Stokes equations.

 is Brownian (standard diffusion),
is Brownian (standard diffusion), 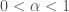 is subdiffusive,
is subdiffusive,  is superdiffusive, and ballistic is
is superdiffusive, and ballistic is 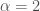 . So the technical definition of anomalous diffusion is
. So the technical definition of anomalous diffusion is 
 is the number of particles,
is the number of particles,  is the location of the particles,
is the location of the particles,  is the diffusion constant, and
is the diffusion constant, and  is the flux of particles.
is the flux of particles.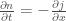

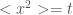
 is superdiffusive, and ballistic is
is superdiffusive, and ballistic is  in certain turbulent regimes.
in certain turbulent regimes.
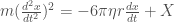
 is a stochastic variable. It is assumed to be zero mean, unit variance, and no time correlations, aka
is a stochastic variable. It is assumed to be zero mean, unit variance, and no time correlations, aka 

