This is part of my “journal club for credit” series. You can see the other computational neuroscience papers in this post.
Unit: Deep Learning
- Perceptron
- Energy Based Neural Networks
- Training Networks
- Deep Learning
Papers
Neural networks and physical systems with emergent collective computational abilities. By Hopfield in 1982.
A Learning Algorithm for Boltzmann Machines. By Ackley, Hinton, and Sejnowski in 1985. (Note: Only section 1 and 2 are covered here, rest of paper covered in next topic).
Other Useful References
- Hopfield Network – Wikipedia and Scholarpedia
- Boltzmann Machine – Wikipedia and Scholarpedia
- MacKay, Ch 31 (optional intro to Ising model), Ch 42 (Hopfield), and Ch 43 (Boltzmann).
- Amit – This provides a detailed, physics-based, analysis of the Hopfield model
Why should you care?
The Hopfield paper provides an explicit, decently biologically plausible, mechanism by which a system of (artificial) neurons can store memories. The central goal of the paper is to demonstrate a method for content-addressible memory. Standard computer memory is location-addressible (ie your computer looks to a specific place on your disk). The idea of content-addressible memory is that a partial (perhaps faulty) presentation of the memory should be sufficient to obtain the full memory. I love this quote:
An example asks you to recall ‘An American politician who was very intelligent and whose politician father did not like broccoli’. Many people think of president [George W.] Bush –even though one of the cues contains an error.
MacKay Ch 38, pg 469.
Hopfield Neural Network
So how does Hopfield actually store memories? The idea is that a system can be constructed such that the stable states of the system are the desired memories. I’m going to change notation from the original Hopfield paper so that it matches standard physics notation.
In the actual paper, Hopfield uses threshold neurons but all arguments can be easily extended to a 





How does the system actually store memories? I will call the memories (

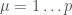

Why are memories actual stable? We can write the activation function of a neuron (also known as the local field in physics terms) as

Now let’s check if a memory is stable (say memory 



The first term of the activation function is exactly what we need for the first neuron to be stable. The second term is noise, but how big is it? We need a couple more facts to figure it out. First, we can safely assume 

So this establishes that memories are stable. But how should we actually think about these memories? By examining the energy of the system, one can show that these memories are global minima and have basins of attraction. The energy is defined as

where we have defined the self-interactions to be zero (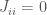
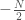
Therefore, using the prescription outlined in the Hopfield paper, one can take a set of memories, 
Boltzmann Machine
Hopfield networks are great if you already know the states of the desired memories. But what if you are only given data? How would you actually train a neural network to store the data?
The next journal club will get to actual training, but it is convenient to introduce at this time a Boltzmann Machine (BM). This is an extension of Hopfield networks that can actually learn to store data. In the most general Boltzmann machine, neurons are divided into visible (actually interact with the data) and hidden (only see data through interactions with visible neurons). This leads to an energy function of:

where 
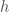
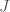

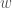
As will be explained in the next journal club, the full Boltzmann machine takes a long time to train. So instead, it is common to use a Restricted Boltzmann Machine (RBM) which has no self interactions amongst layers:
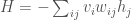
Fundamental Questions
- Why is content-addressible memory considered associative, software and hardware fault tolerant, and distributed? Why is this closer to biology than location-addressible memory?
- Why is the Hopfield storage prescription Hebbian?
- Do the calculation to show that the memories are global minima.
- Hopfield says “In many physical systems, the nature of the emergent collective properties are insensitive to the details inserted in the model.” What are some assumptions that Hopfield relaxes in the simulations?
- Next time we will see that RBMs are easier to train to BM. Can you see why?
Advanced Questions
- For the activation function argument, what is the standard deviation of the noise term? What does that imply about stability of memories?
- What happens to the capacity if the memories are not equally
and/or correlated with each other?

 , that are fed into the perceptron, with each input receiving its own weight,
, that are fed into the perceptron, with each input receiving its own weight, 
 , to determine the output,
, to determine the output,  . There are lots of different possible activation rules with some popular ones including
. There are lots of different possible activation rules with some popular ones including



 , where each entry
, where each entry 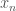 is
is 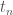 . Then training proceeds by seeing if the output label of a perceptron matches the correct label. If everything is correct, perfect! If not, we need to do something with that error.
. Then training proceeds by seeing if the output label of a perceptron matches the correct label. If everything is correct, perfect! If not, we need to do something with that error.![\mathcal{E} = - \sum_n \left[ t_n \ln y_n + \left(1-t_n \right) \ln \left(1-y_n \right) \right]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BE%7D+%3D+-+%5Csum_n+%5Cleft%5B+t_n+%5Cln+y_n+%2B+%5Cleft%281-t_n+%5Cright%29+%5Cln+%5Cleft%281-y_n+%5Cright%29+%5Cright%5D+&bg=ffffff&fg=444444&s=0&c=20201002)
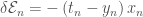 .
. . This is a greedy algorithm (always improves current error, longterm consequences be damned!). Gradient descent comes in several closely related varieties: online, batch, and mini-batch. Let’s start with the mini-batch. First the data is divided up into small random sets (say 10 data points each). Then we loop through the mini-batches, and for each one we calculate the output and error and update the weights. Online learning is when the mini-batches each contain exactly 1 data point, while batch learning is when the mini-batch is the whole dataset. The current standard is to use a mini-batch of between 10 to 100 which is a compromise between speed (batches are faster) and accuracy (online finds better solutions).
. This is a greedy algorithm (always improves current error, longterm consequences be damned!). Gradient descent comes in several closely related varieties: online, batch, and mini-batch. Let’s start with the mini-batch. First the data is divided up into small random sets (say 10 data points each). Then we loop through the mini-batches, and for each one we calculate the output and error and update the weights. Online learning is when the mini-batches each contain exactly 1 data point, while batch learning is when the mini-batch is the whole dataset. The current standard is to use a mini-batch of between 10 to 100 which is a compromise between speed (batches are faster) and accuracy (online finds better solutions).